Evolving Sounds: From Research to Product — Technical Details
For the past few years, I have been researching how Quality Diversity (QD) algorithms can be applied to sound synthesis. The basic idea is straightforward: instead of optimising for a single "best" sound, QD algorithms search for many different high-quality sounds across a space of possibilities. The result is a diverse collection of sounds that might never have been conceived by a human designer.
Now I am working on bringing this research to a wider audience. This post summarises what I have been considering and working on so far.
Being haunted by sounds from the past
Through conversations with sound designers, composers, and music producers, a pattern emerged. Many described feeling stuck in repetitive workflows, reaching for the same sounds and techniques. The term that kept coming up was "creative ruts."
There is a deeper issue underneath this. Most accessible sonic material has been heard before. Sample libraries offer professionally produced sounds, but they are sounds that already exist. AI music tools train on existing recordings, learning to produce variations within the space of what has already been created. Even synthesiser presets represent frozen snapshots of what someone else thought sounded good.
This creates what might be called a hauntology of sound: creative work that cannot escape the gravity of its influences because the raw materials themselves carry those influences. To develop a distinct sonic identity, creators need exposure to sounds that do not carry this baggage.
What the system actually does
Currently, the core of the system uses neural networks called CPPNs (Compositional Pattern Producing Networks) to generate audio. These networks produce patterns that drive Web Audio API synthesis graphs. The patterns determine how oscillators, filters, and other audio components behave over time.
These sounds are not trained on existing audio. They evolve from simple beginnings through mutation and selection, following principles closer to biological evolution than machine learning. The sounds that emerge have no direct ancestry in human music production.
A QD algorithm called MAP-Elites manages the evolutionary process. It maintains a grid of "niches," each representing a different type of sound. When a new sound is generated through mutation, the algorithm checks whether it is better than the current occupant of its niche. If so, it replaces it. Over thousands of generations, this process fills the grid with diverse, high-quality sounds.
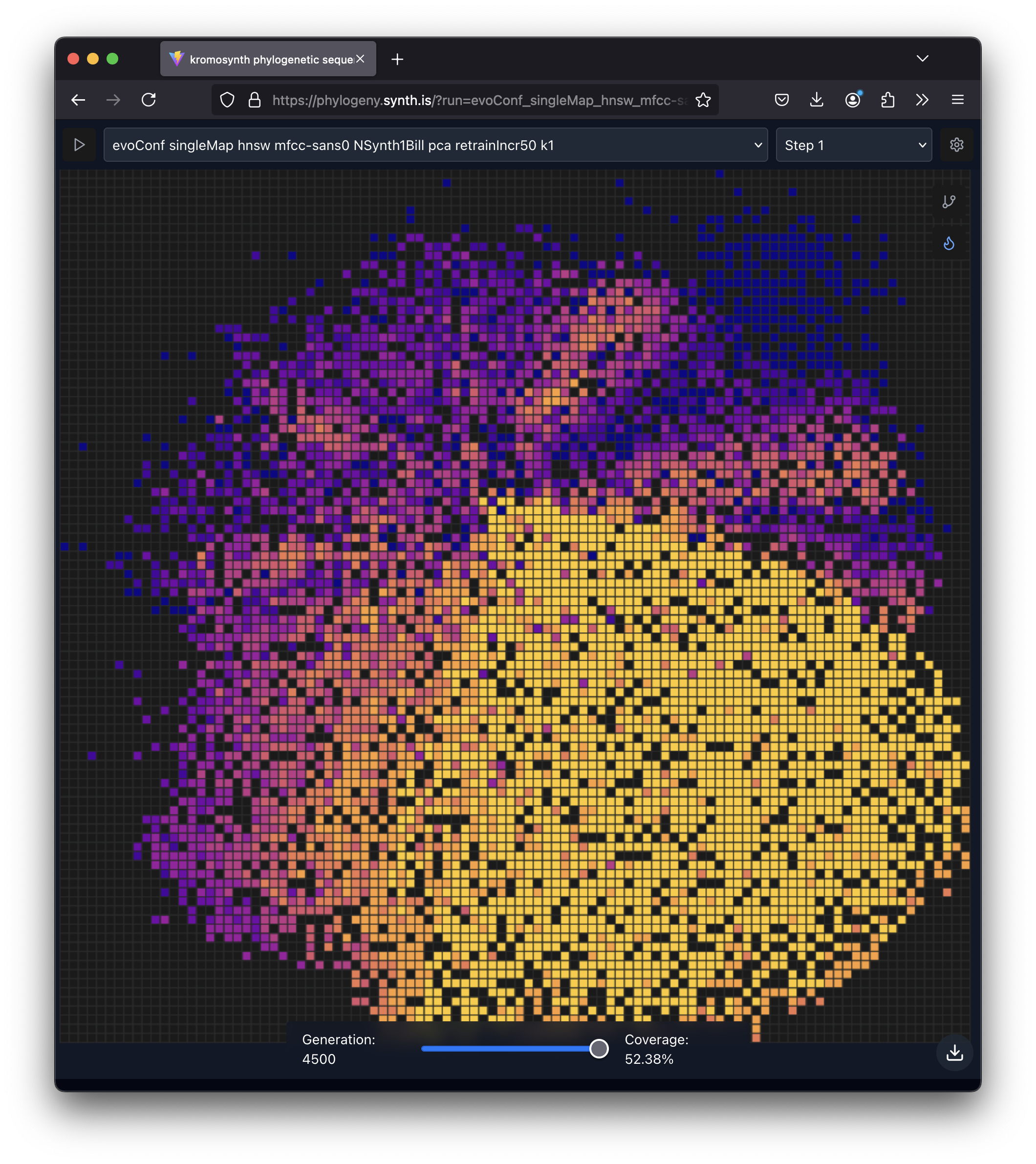
A MAP-Elites archive visualization: each cell represents a niche in the sound space, colored by quality. Over thousands of generations, the algorithm fills this grid with diverse, high-quality sounds.
The challenge is defining what makes sounds "different" in a meaningful way. My earlier work used audio features called MFCCs (Mel-frequency Cepstral Coefficients), reduced to two dimensions using PCA. This worked, but the resulting sounds often felt perceptually similar despite occupying different grid positions.
Recent technical work
Better behaviour descriptors
I've exploring ways to implement a more sophisticated approach to measuring sound diversity. One approach is to use CLAP (Contrastive Language-Audio Pretraining) to extract 512-dimensional embeddings from audio. These embeddings capture semantic properties of sounds in a way that aligns better with human perception.
On top of this, I am training a projection network using triplet loss. The idea comes from a technique called QDHF (Quality Diversity through Human Feedback). By learning which sounds humans consider similar or different, the system can discover what dimensions of variation actually matter to listeners.
Improved search efficiency
The standard MAP-Elites algorithm uses random mutation, which can be inefficient. I have started work on integrating CMA-MAE (Covariance Matrix Adaptation MAP-Annealing), which uses smarter search strategies borrowed from numerical optimisation. The jury is still out on its effectiveness in this context.
Quality filtering
One persistent problem with evolutionary sound synthesis is noise. QD algorithms naturally maximise diversity, which means they will happily fill niches with random static if nothing penalises it. I have built a multi-stage quality evaluation pipeline that filters out obviously unmusical sounds before they enter the archive. This includes checks for signal-to-noise ratio, spectral clarity, and harmonic content.
Surrogate prediction
Audio rendering is computationally expensive. I am experimenting with a surrogate model that predicts sound quality directly from the genome (the network structure and weights) before rendering audio. If this works reliably, it could reduce computation by 60-90% by filtering unpromising candidates early.
Who might find this useful
The people I have spoken with fall into several groups:
Sound designers who get stuck in repetitive workflows. They spend money on sound discovery already (Splice subscriptions, sample packs) and are looking for ways to break patterns.
Film and television composers who work under deadline pressure and need to differentiate their work. They are often averse to subscriptions but will pay for tools that help them avoid derivative output.
Technical sound explorers who struggle to realise preconceived sounds through conventional synthesis. They are interested in collaborative approaches to discovery.
DIY composers who are happy within their existing sonic vocabulary but open to expanding it. They might appreciate unique discoveries even if they were not actively seeking them.
Live performers and researchers who value interactivity and community. They want to see what others are discovering, not just browse a static catalogue.
What these groups share is an appreciation for sounds that surprise them, that they would not have thought to look for.
Two directions for the product
Beyond the core CPPN-based sound generation, I am exploring two complementary approaches that could define how this technology reaches users.
Exploring existing plugins with QD
Most electronic music producers own synthesiser plugins they have barely scratched the surface of. Serum, Massive, Diva, and similar tools have hundreds of parameters. Users typically stick to presets or make small manual adjustments, leaving vast regions of the parameter space unexplored.
The idea here is to let QD algorithms systematically explore a user's own plugins. The system loads a VST, enumerates its parameters, and then searches for diverse, high-quality sounds by varying those parameters and evaluating the results.
This idea is inspired by the DGMD (Dataset Generator for Musical Devices), by Stefano Fasciani ebt al., who has co-supervised my PhD project. We've discussed this research angle a bit and I'm very much interested in collaborating with them on investigating it further. The implementation could use DawDreamer, a Python library that can host VST plugins, send MIDI, render audio, and expose parameters programmatically. This means the approach would work with any plugin, including commercial closed-source ones. We do not need access to the plugin's internals — we just twiddle knobs and listen to what comes out.
This sidesteps the sample library market entirely. Instead of selling sounds, the value proposition becomes: discover what your existing tools can do. Users keep working with plugins they already know and own, but gain access to sonic territories they would never have found manually.
Distributed evolution with a shared community tree
Running QD searches is computationally intensive. One model is to run everything centrally, but this creates costs that need recovering through subscriptions or purchases. An alternative is to distribute the computation.
The architecture I have been considering lets individuals run evolution processes locally on their own machines via a desktop application. Their discoveries sync back to a central server, which aggregates contributions into a shared community tree. Users running local evolution see the full detail of their own runs. Web visitors browsing the community tree see a curated view containing only the interesting discoveries: elites, sounds that other users adopted, and genomes that exceed quality thresholds.
This creates a few interesting dynamics:
Shared benefit from distributed compute. Users who contribute processing power help populate the community archive. The more people participate, the richer the shared resource becomes.
Phylogenetic lineage as community property. The evolutionary history of sounds becomes something collective rather than locked inside a single company's servers. You could trace how a sound you like evolved, who contributed its ancestors, and what branches of exploration led to it.
Collaboration through observation. Users can see what others are discovering, how they are interacting with sounds, and what branches of the evolutionary tree are attracting attention. This is different from passively browsing a catalogue; it is watching a shared exploration unfold.
Trust and quality control. Not all contributors are equal. The system would need reputation mechanisms and sampling-based verification to prevent low-quality or malicious contributions from polluting the archive.
Deep linking between local and global. Custom URL schemes could let users jump from a sound they find in the community tree directly into their local application to explore that lineage further, or vice versa.
This is architecturally complex and I have not yet built it. But it represents a different relationship between platform and users than the typical centralised model. Also, it's entirely uncertain whether users would find it appealing enough to participate: this distributed approach is inspired by old projects like SETI@home, Folding@home and even Electric Sheep, but those had and have clear altruistic motivations that may not translate to music production. Perhaps this way of distributing computing tasks was more relevant in an era when it was more common to have powerful personal computers (for the time) sitting idle for long periods. Now mobile devices dominate, which are commonly shut down when not in use. Perhaps there is still a niche of dedicated enthusiasts who would run such software on gaming rigs or workstations. Only experimentation will tell.
Alternative synthesis approaches
While CPPN-based synthesis is the core of my research, I am also exploring other directions.
One possibility is using large language models to generate Faust code. Faust is a functional programming language for audio DSP that compiles to various targets including WebAssembly. An LLM could generate synthesiser designs from text descriptions, and QD algorithms could explore variations systematically.
This would complement rather than replace the CPPN approach. Faust offers capabilities that the Web Audio API lacks, particularly single-sample feedback for physical modelling and more sophisticated filter designs. A hybrid system where CPPNs generate control signals for Faust-defined synthesis structures could access sonic territories neither approach reaches alone. This last approach is perhaps something I should prioritise after validating the CPPN-based work in a social setting.
The product question
Turning research into a product that people actually want to use is a different problem from the research itself.
I've received grants from The Research Council of Norway and the Iceland Technology Development Fund to explore the viability of this technology as a commercial product. As part of that, I have spoken with electronic music producers about their workflows and pain points. A few things became clear:
Desktop integration matters. Almost every producer I interviewed uses a DAW (Digital Audio Workstation) as their central tool. A web-only solution is not sufficient. Sounds need to be easily loadable into their existing setup.
Subscriptions are unpopular. The producers I spoke with, generally aged 30-50, strongly prefer one-time purchases over monthly subscriptions. This is the opposite of what typical SaaS advice suggests, but it matches the culture of the music production tools market.
Discovery is the value proposition. Sample libraries already exist in abundance. What producers struggle with is finding genuinely novel sounds that break them out of familiar patterns. The evolutionary approach offers something different: sounds that nobody asked for, because nobody knew to ask.
How this differs from existing options
Looking at what is available today:
Splice offers vast libraries with professional curation, but the sounds come from known genres and lack surprise. You find what you are looking for, but you are unlikely to find what you were not looking for.
Soundly provides quick access to sound design and discoveries made by others, but it is consumption-oriented. There is no community influence on what gets discovered or how.
Noisli and similar ambient sound apps offer curated background sounds, but interaction is limited to mixing existing material.
None of these offer collaboration in the discovery process itself. None generate sounds from first principles. None let you see the evolutionary history of how a sound came to exist.
Delivery formats
For the CPPN-generated sounds, I am building a service that renders evolved sounds into sample-based virtual instruments. The approach is to generate SFZ files (a widely supported open format, which I've experimented with before) natively, then use a conversion tool called ConvertWithMoss to produce versions for specific platforms like Ableton, Logic, and Kontakt, and other popular VI formats, like Decent Sampler.
The pipeline will handle velocity layers (different sounds at different playing intensities) and can sample across the pitch range. More advanced features like round-robins (multiple variations of the same note) might also be a part of it.
This will hopefully offer one useful step towards integrating evolved sounds into existing workflows. Users can load the instruments into their DAW of choice and play them like any other virtual instrument. An ultimate goal could be to have a VST/AU plugin that directly connects to the evolutionary discovery system, but starting with sample-based instruments is more straightforward.
What I am uncertain about
Several questions remain open.
Will the quality filtering be good enough? The current system catches obvious noise, but distinguishing "interestingly weird" from "unpleasantly weird" is subjective. Human curation will likely remain necessary.
How do people want to browse evolutionary discoveries? The phylogenetic trees that show how sounds evolved are intellectually interesting, but I do not know whether they provide practical value for musicians looking for sounds to use.
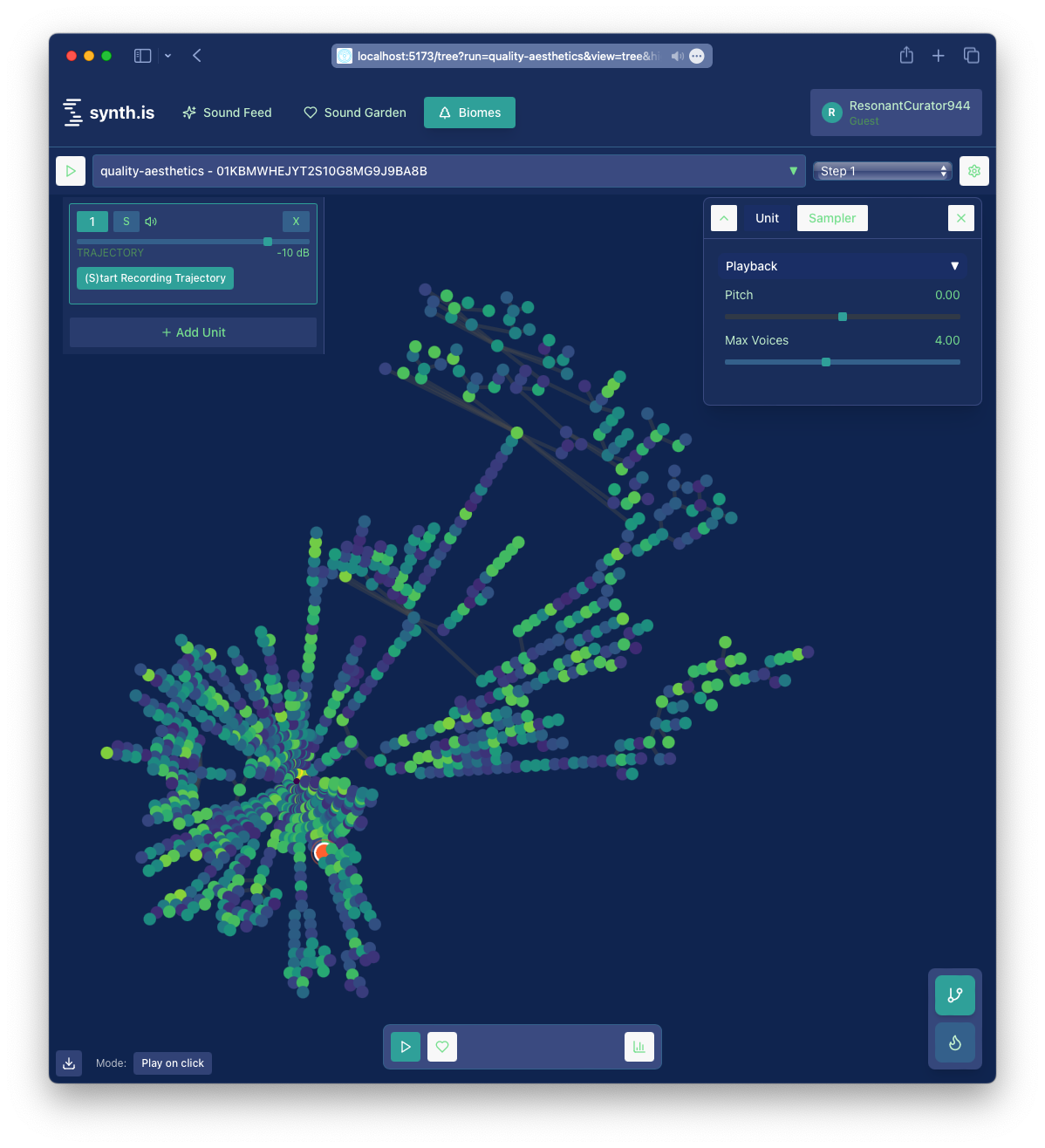
This phylogenetic tree illustrates the evolutionary relationships between different sounds, highlighting a single sound in its evolutionary context evolved during a QD process. This view-state was arrived at after navigating from one of the simpler views, by choosing to navigate to the tree from one of the sounds in a feed or one's curated sound garden.
An Instagram-like feed could work as a complementary entry point. Swipe-based discovery with simple like/skip gestures is lower commitment than navigating a tree structure. User likes could feed back into the QD process as human-in-the-loop evaluation — this connects to the QDHF work, where likes become implicit similarity judgments that can retrain the projection network. Users who find something interesting through the feed could then be offered the phylogenetic view ("See how this sound evolved") as an optional deep dive rather than the default interface.
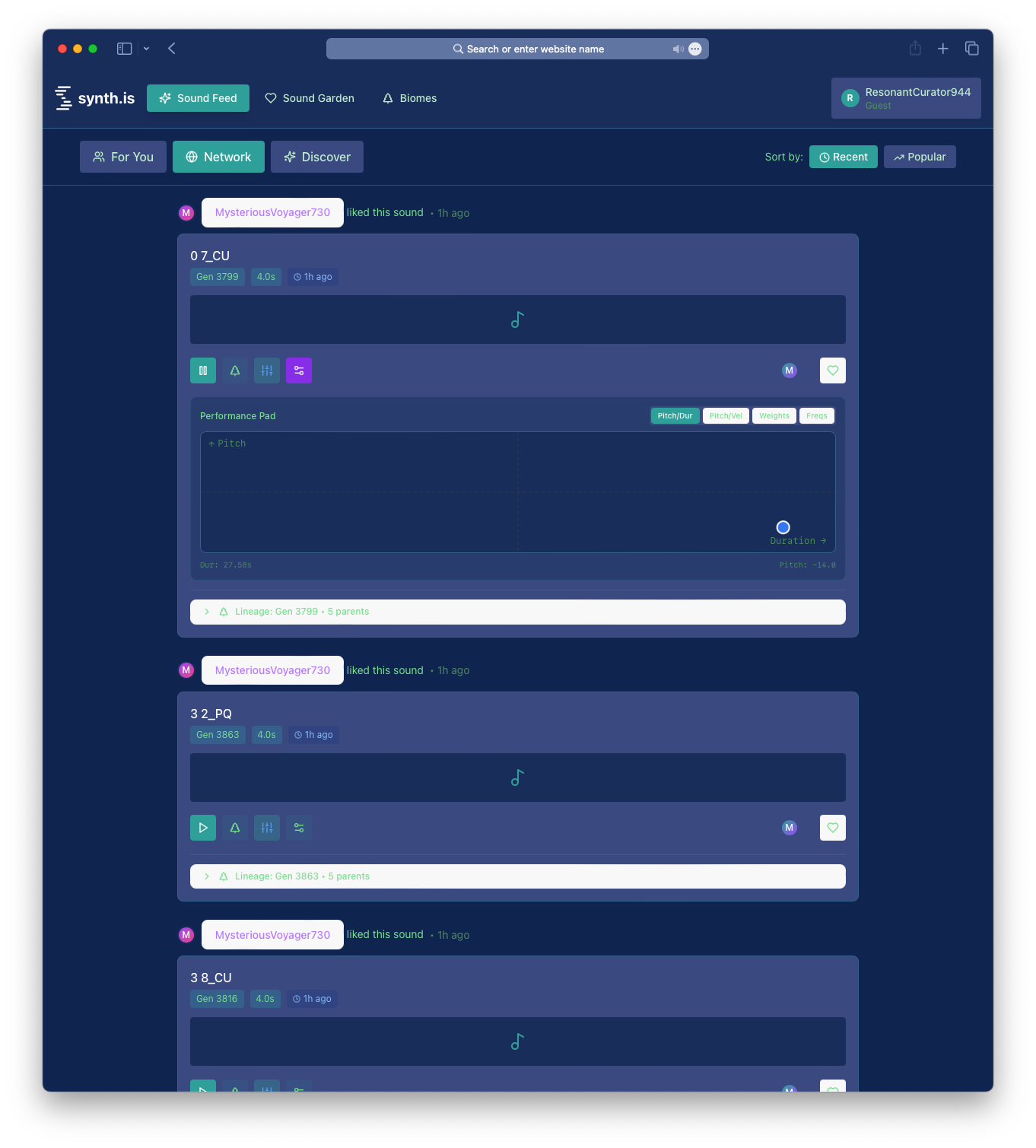
A prototype feed interface showing sound discovery: users are presented with a feed of sound-discovery-activity from the network, showing events such as likes by other users, making sound exploration more accessible than navigating phylogenetic trees.
The risk is that this flattens the evolutionary structure into just another content feed, losing what makes the approach distinctive. The question is whether casual users need to understand the evolutionary process to benefit from it, or whether that's something only power users care about.
Is there actually a market? The producers I interviewed were enthusiastic about the concept, but enthusiasm in an interview does not translate directly to purchases. The only way to find out is to ship something and see.
The question is what constitutes a minimum viable test. The full distributed architecture and VST exploration are not necessary to validate whether people want evolved sounds. The core CPPN system works. A curated collection of discoveries — even as a simple sample pack or SFZ download — could test whether anyone engages. The film/TV composers under deadline pressure might be the most motivated early users: they have immediate needs and budgets.
It is possible to keep investigating indefinitely. At some point the only way to know is to put something in front of specific people and watch what they do with it. Interviews tell you what people say they want; actual usage tells you what they actually do. This is not "build it and they will come" — the sounds will not market themselves. But there is a difference between publishing to a website and hoping for traffic, versus inviting people who have already signed up to a mailing list to try a beta version and seeing whether they engage.
What is the right business model? One-time purchases align with user preferences but create pressure for constant new releases. Credit systems or limited free tiers might work, but the details matter enormously. The distributed model complicates this further — how do you monetise when users contribute the compute?
Which approach to prioritise? VST parameter exploration, distributed CPPN evolution, and LLM-based Faust generation are all interesting directions. Trying to build all three simultaneously would spread effort too thin. I need to pick one to validate first. Currently I'm leaning towards extending the current CPPN-DSP sound synthesis approach to something that could be called CPPN-DSP-Faust, where CPPNs generate control signals for Faust-defined synthesis structures, still evolved with NEAT and QD.
Current state
The technical infrastructure for the core QD-based discovery system, utilising CPPN-DSP based sound synthesis, is largely in place. The QD search runs (fairly) reliably, quality filtering (somewhat) works, and the virtual instrument rendering service is close to producing usable output. The web application provides basic browsing and playback.
The VST exploration is at an early idea stage. The distributed architecture exists as planning documents and task breakdowns but no implementation yet.
What remains is testing, refinement, and finding out whether any of this is useful to people outside my own research bubble.
I am treating the next few months as a validation exercise. If people engage with the sounds and find value in the evolutionary discovery process, there is something worth building further. If not, that is useful information too.
This post reflects work in progress. Technical details may change as development continues.